1. Introduction
The mechanisms driving language variation and change remain a central debate in language evolution research, with competing hypotheses emphasizing either stochastic processes (e.g., [
1,
2]), functional adaptation (e.g., [
3,
4,
5]), cognitive constraints (e.g., [
6,
7]), system-internal structural dynamics (e.g., [
8,
9]), or their interplay (e.g., [
10]). Among these, functionalist accounts, particularly those within usage-based linguistics, posit that language adapts to meet communicative needs in real-world contexts (e.g., [
11,
12,
13]), which is grounded in the perspective that human language functions as a tool for communication [
14].
Building on this functionalist view, a large body of research in linguistics and cognitive science has sought to provide a unified explanation for various linguistic phenomena through the principle of communicative efficiency, which states that linguistic structures are shaped partly by the need to support efficient communication (e.g., [
3,
4,
5]). Specifically, communication needs to achieve a level of efficiency that avoids overburdening the speaker while providing sufficient information for the listener to facilitate successful interaction. This requires language to simultaneously reduce processing costs through simplicity and maintain informativeness to ensure that the listener can interpret the speaker’s intended messages. In addition to its significant role in communication, simplicity enhances language learnability, as learners more readily acquire simpler systems [
15].
Previous research has demonstrated that the principle of communicative efficiency can account for numerous linguistic patterns, such as the tendency for more frequent words to be shorter (Zipf’s law of abbreviation) [
16] and for homophonous words to be more frequent and shorter as well [
17]. However, efficiency-like patterns do not necessarily imply functional adaptation, as stochastic processes, such as random drift, may produce superficially similar outcomes. For example, random typing models predict that even if a monkey randomly types on a typewriter, with spaces marking word boundaries, the characters generated by this random process would still follow Zipf’s law of abbreviation [
1,
18]. This occurs because when the probability of inserting a letter and a space adds up to 100%, each additional character decreases the chance that a space will immediately follow to mark the end of the word. As a result, shorter strings are more likely to emerge than longer ones, not as adaptations for communicative efficiency but as a statistical artifact of random processes. This tension underscores a critical methodological challenge: distinguishing genuine efficiency-driven adaptation from epiphenomenal byproducts of non-functional mechanisms. Therefore, clarifying the role of communicative efficiency requires null hypothesis testing, as communicative efficiency gains empirical validity only if human languages prove to be more efficient than artificial systems generated by null models devoid of communicative pressures.
Recent advancements in null modeling have provided further insight into the debate. These models simulate linguistic systems under constraints such as phonotactics, semantic patterns, or lexical longevity while explicitly excluding communicative pressures. Some studies have shown that artificial lexicons generated through such models can replicate homophony-frequency and homopony-word length correlations observed in natural languages or even outperform real-world lexicons in efficiency metrics [
19,
20,
21]. These findings suggest that phonotactic biases or lexical aging (older words accumulating homophones over time) may suffice to produce seemingly efficient structures. Thus, efficient-looking patterns in natural languages might arise independently of direct communicative pressures.
Conversely, a follow-up study finds that null models fail to replicate the efficiency found in natural languages under certain conditions, particularly when the distribution of meanings more closely approximates that found in human languages [
22]. Moreover, another study, which tested the functionalist account against null models, presents a mixed picture: some linguistic changes are driven by stochastic processes, while others do not occur by chance, indicating that selective pressures for efficient communication are likely at play in certain linguistic phenomena [
10]. The divergent results highlight that efficiency-like patterns can arise from multiple pathways, which complicates the identification of communicative pressures as the specific driving force behind linguistic change. Meanwhile, micro-level empirical studies that do not rely on simulation models have also raised questions about the explanatory power of the efficiency account (e.g., [
23,
24]). For instance, certain harmonious word orders, in which syntactic structures follow a consistent directional pattern (e.g., all modifiers preceding heads), are argued to arise from the shared origin of these structures rather than being directly driven by communicative efficiency [
25]. Consequently, the role of communicative pressures in the emergence of efficient linguistic patterns remains an unresolved, debatable issue.
Against the backdrop presented above, we review five recent studies on communicative efficiency published in the
Proceedings of the National Academy of Sciences of the United States of America (PNAS) over the past five years (2020–2024). We begin by providing a general overview of how efficiency is conceptualized and measured in terms of simplicity and informativeness in information-theoretic terms, establishing the methodological foundation for these studies. Subsequently, we assess their contributions to three unresolved questions in the field: (1) can the principle of communicative efficiency provide a unified account of previously under-studied linguistic phenomena? (2) how do linguistic systems achieve and maintain efficiency? (3) what additional factors, beyond communicative pressures, influence language evolution? Following a synthesis of the findings, we provide a broader discussion of the contributions of these studies, acknowledge remaining challenges to the efficiency account, and outline potential directions for future research. Finally, we conclude by integrating the key insights.
2. Assessment of Communicative Efficiency
The two core parameters of communicative efficiency,
i.e., simplicity and informativeness, exhibit a dynamic tension, as established in prior research (e.g., [
26,
27,
28]). While increasing informativeness, for instance, by incorporating more specific terms, can improve clarity and precision, it also leads to greater complexity in language, which may hinder language learning and processing. Conversely, simplifying language, such as by reducing the number of terms, can alleviate cognitive loads but may compromise its capacity to convey detailed and explicit information. This may result in ambiguity and vagueness. Therefore, The efficiency hypothesis proposes that linguistic systems evolve to optimize the trade-off between these competing pressures to support efficient communication.
In computational modeling approaches, the simplicity-informativeness trade-off is often operationalized through inversely related complexity and information loss measures. Complexity is typically quantified by metrics such as the number of linguistic items within a category or the length of linguistic forms (e.g., [
28,
29]). In contrast, information loss pertains to a reduction in the amount of information successfully transmitted from the speaker to the listener during communication [
30], which appears to be hardly measured. Nevertheless, drawing upon the mathematical framework of information theory [
31,
32,
33], information loss can be quantified using established metrics such as entropy and Kullback-Leibler (KL) divergence. Entropy measures the uncertainty or unpredictability associated with information content [
31], whereas KL divergence, often referred to as relative entropy, quantifies the divergence between one probability distribution and a second probability distribution [
34].
To illustrate, consider a scenario in which a speaker uses a vague expression, for example, saying “on the desk” instead of specifying “in the left corner of the desk”. This choice reduces the entropy of the message, as it simplifies the utterance by using a more general term. However, simplification as such increases the cognitive load on the listener, who, under this circumstance, has to consider multiple possible interpretations (e.g., the left, right, or center of the desk). As a result, the listener’s understanding becomes more uncertain. The amount of information lost due to such vagueness can be quantified using KL divergence, which captures the gap between what the speaker intends to convey (a specific referent) and what the listener infers (a distribution over possible referents).
KL divergence is calculated using the formula in (1) where
x represents the set of possible referents (e.g., “left corner”, “right corner”, “center” of the desk). The distribution
P(
x) reflects the speaker’s intended meaning. If the speaker intends to mean the left corner, then
P(left) = 1,
P(center) = 0, and
P(right) = 0. In contrast,
Q(
x) represents the listener’s interpretation upon hearing the vague phrase “on the desk”. In the absence of further context, the listener may assign equal probabilities to each possible referent, such that
Q(left) =
Q(right) =
Q(center) = $$1 / 3$$.
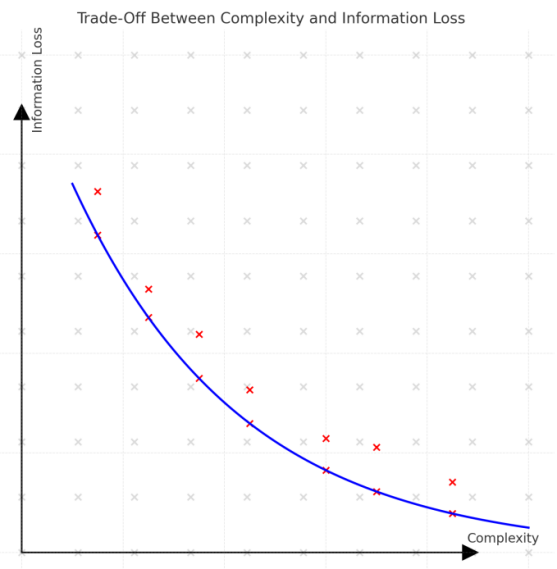
Employing these measures, the efficiency of attested linguistic structures can be quantified and mapped onto a two-dimensional space that captures the trade-off between complexity and information loss. Efficient linguistic systems are expected to fall near or on the Pareto frontier, which represents the set of optimal trade-offs where reducing complexity inevitably leads to increased information loss, and decreasing information loss necessarily requires higher complexity. The trade-off can be illustrated in
, which shows that different linguistic systems may occupy different positions along the Pareto frontier, reflecting different strategies for balancing complexity and information loss.
. Trade-off between complexity and information loss. The blue curve represents the Pareto frontier, while the red symbols represent attested linguistic systems that are optimal or near-optimal.
3. Efficiency Analyses of the Lexicon and Grammar
The two studies reviewed in this section examined communicative efficiency at the lexical and grammatical levels, respectively, providing evidence that the principle of communicative efficiency can serve as a plausible interpretation for both the forms and meanings of different linguistic items.
3.1. The Lexicon
There are two main lexicalization strategies for expressing novel concepts: word reuse and compounding. Word reuse involves extending the meaning of an existing word to denote a new concept, as seen in the extension of
cloud from “meteorology” to “digital storage”, which leads to the phenomenon of polysemy. Compounding, on the other hand, combines two words or morphemes to form new terms (e.g.,
smartphone). Word reuse is considered an economical lexicalization strategy, as it introduces no additional terms into the vocabulary [
17]. Moreover, since the different senses of a reused word are often conceptually related, reused words typically require less cognitive effort for learning and understanding [
35]. In contrast, compounding frequently generates longer lexical forms but exhibits greater semantic transparency, rendering it more informative, as the meaning of a compound can often be inferred from its components [
36].
Despite extensive discussion in prior literature on the lengths and meanings of words, the two strategies have been examined independently without a unified framework that connects them. Xu et al.’s study [
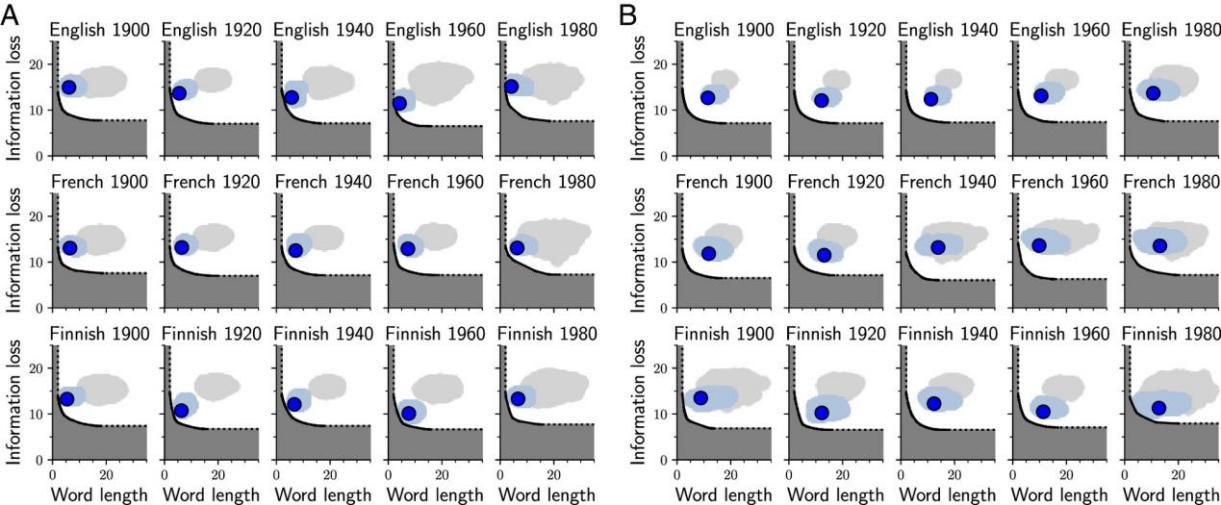
37] addresses this gap by examining the efficiency of both strategies in three languages, namely, English, French, and Finnish. The researchers assessed the complexity of attested reused words and compounds based on word length and quantified information loss using KL divergence. Their findings, as illustrated in
, show that attested items from both strategies are positioned closer to the Pareto frontier compared to near-synonyms and randomly selected words. This observation indicates that both strategies represent efficient solutions, consistent with the principle of communicative efficiency. Furthermore, aligning with prior studies (e.g., [
17,
35,
36]), the results demonstrate that word reuse and compounding prioritize simplicity and informativeness, respectively, which results in their different positions relative to the Pareto frontier.
. Efficiency analyses of word reuse and compounding Panels (<b>A</b>,<b>B</b>) illustrate the word reuse and compounding results, respectively. The black curve represents the Pareto frontier, while the blue, light blue and gray areas correspond to attested items, near-synonyms, and random words, respectively. This graphic is from [
37], licensed under the CC BY-NC-ND 4.0 license.
The researchers also compared literal and non-literal expressions within each strategy. Literal terms (e.g.,
birthday card) are characterized by semantic transparency, whereas non-literal expressions (e.g.,
blue-collar, denoting a category of manual labor workers) often rely on figurative or metaphorical interpretations. The study reveals that literal expressions are more efficient than non-literal ones in both strategies, as their semantic transparency leads to a higher level of informativeness. These findings suggest that the efficiency framework should be capable of capturing variations not only across strategies but also within each strategy.
Overall, the study provides a unified framework that integrates word reuse and compounding as efficient lexicalization strategies. It also highlights the critical balance between word length and informativeness in achieving efficiency. This challenges the prior claim that natural lexicons are closer to non-optimality, a conclusion based on a form-biased criterion that overlooked informativeness [
38].
Nonetheless, while the study demonstrates the compatibility of both word formation strategies with the efficiency account, it does not rule out the possibility of alternative mechanisms contributing to observed lexical optimization, such as semantic constraints or the longevity of words, which are not directly related to communicative pressures. Although constructed baseline lexicons were found to show lower efficiency relative to natural lexicons, the experimental design did not fully isolate communicative pressures during lexicon construction or control for other potential influencing factors. As a result, the findings reported in the study remain compatible with alternative explanations, as substantiated by prior research (e.g., [
19,
20,
21]).
Additionally, as the study emphasizes uniformity over differentiation, it leaves room for further investigation into the alternation between these two strategies, both within a single language for different concepts and across languages for the same concept. In other words, the remaining questions concern which concepts favor lexical reuse versus compounding and whether there are cross-linguistic variations. As noted by the researchers (p. 7), communicative needs may influence a language’s preference for one strategy over another. Specifically, concepts with higher communicative needs are less likely to be expressed by compounds, as minimizing word length aligns with the Principle of Least Effort [
16]. Zipf’s principle posits that higher-frequency words tend to be shorter, thereby minimizing cognitive effort in communication. Likewise, differences in local communicative needs may account for the varying strategies used to express the same concept across languages, reflecting cultural influences on lexicalization.
To further test the utility of the efficiency account, future studies could extend their scope beyond word reuse and compounding to encompass other lexicalization strategies, such as derivation, which produces longer yet more informative words compared with word reuse.
3.2. Grammar
Given that both lexical items and grammatical markers represent form-meaning pairs, the principle of communicative efficiency should theoretically extend to grammatical markers as well if it is applicable to the lexicon. Previous research has shown that lexical items partition semantic domains into fine-grained meanings, achieving a balance between simplicity and informativeness (e.g., [
3,
5,
39]). For instance, the color domain is systematically partitioned into distinct color terms, such as “red”, “black”, “white” and “green”, with an efficient trade-off between informativeness for differentiating hues and simplicity for minimizing memory load [
28]. Similarly, grammatical markers are expected to partition grammatical domains in an efficient way. However, most prior studies have concentrated on the relationship between the length of grammatical markers and their usage frequency. A notable study by Haspelmath [
40] demonstrates that more frequently used grammatical constructions tend to be zero-marked, whereas less frequently used constructions are explicitly marked. For example, plural forms as less frequent structures often include additional markers, such as the plural suffix
-s in English, resulting in longer forms compared to singular words. This pattern reflects how language economizes effort for more common constructions while maintaining clarity and informativeness through longer forms for less common ones.
By comparison, the issue of how grammatical markers partition specific grammatical domains has received relatively limited scholarly attention. Thus, Mollica et al. [
41] conducted a study to examine both the forms and meanings of grammatical markers through the lens of communicative efficiency. Their investigation focused on the grammatical features of number, tense, and evidential marking, encompassing 37 languages for number and over 100 languages for the other two features. Number refers to the quantity of entities involved in an event, typically distinguishing between singular and plural; tense indicates the timing of an action or state relative to the moment of speaking, commonly categorized into past, present, and future; evidentiality conveys the source of information, often differentiating between firsthand and secondhand evidence.
Under an information-theoretic framework, the researchers calculated information loss through entropy measures. For the analysis of meanings, they assessed complexity by examining the number of distinctions made for each grammatical feature. In contrast, complexity was measured based on the length of grammatical markers for the analysis of forms. Their findings reveal that attested grammatical inventories achieve near-optimal trade-offs between complexity and information loss for both meaning and form. Thus, they are positioned closer to the Pareto frontier compared to unattested, counterfactual inventories. Furthermore, aligning with prior research (e.g., [
17,
40], the study highlights the correlation between frequency and code length, demonstrating that code length tends to decrease as usage frequency increases. Nonetheless, this study challenges the notion that frequency alone correlates with code length. Instead, it argues that an efficient grammatical system must also satisfy the need for informativeness.
The study contributes to the theory of efficient communication by integrating the meaning and the form of grammatical markers within a unified framework. Nevertheless, it remains subject to debate whether communicative efficiency is the driving force behind efficient grammatical systems. Similar to Xu et al.’s study on word reuse and compounding [
37], the study at issue did not control for other potential influencing factors in its methodological design. While the observed efficient systems align with the efficiency account, therefore, their emergence cannot be conclusively disentangled from alternative mechanisms unrelated to communicative pressures.
Furthermore, the study’s reliance on generalizing from large datasets entails certain methodological simplifications that may not fully capture the multifaceted nature of grammatical markers. For example, grammatical markers usually serve multiple functions simultaneously, such as encoding tense, aspect, and modality. The multifunctionality means that some grammatical markers convey bundled grammatical information rather than operating as dedicated signals of a single grammatical category. Besides, as noted by the researchers (p. 7), some grammatical features enhance the predictability of the subsequent content, which adds to their overall informativeness. To maintain analytical manageability, however, the researchers focused on individual functions at a time. The practice may underestimate the cumulative informativeness of these markers. Future work could adopt a more nuanced approach to investigate how the efficiency principle accounts for the multifunctionality of grammatical markers.
Also, broadening the scope to include a wider range of strategies would provide a more comprehensive perspective. For instance, some languages (e.g., Mandarin Chinese) rely primarily on temporal adverbs or contextual cues rather than inflectional tense markers to indicate the relative timing of events. Exploring these alternative strategies could enrich our understanding of how distinct strategies reflect optimization for efficient communication.
4. Mechanisms for Achieving Communicative Efficiency
Apart from identifying efficient linguistic structures and associating them with the need for efficient communication, it is equally crucial to explore how languages achieve efficiency. One possibility is that languages are predisposed to generate efficient structures. Alternatively, both efficient and inefficient structures may initially emerge, but through processes such as selection or random shifts, inefficient structures are modified or replaced, thus making languages evolve into more efficient ones. The first study reviewed in this section highlights the significance of creation bias in shaping efficient vocabularies, while the second one emphasizes the influence of selection in driving word order towards supporting efficient communication.
4.1. The Lexicon
A recurring pattern in the lexicons of the world’s languages is the under-representation of similar or identical consonant sequences. Experimental evidence suggests that the cross-linguistic tendency is attributable to increased cognitive loads in language production and comprehension, as the brain has to make a greater effort to distinguish articulatory and acoustically similar sounds (e.g., [
42,
43]). Consequently, languages tend to avoid similar or identical adjacent consonants to enhance communicative efficiency.
Regarding the evolutionary dynamics underlying the pattern of consonant avoidance, Cathcart [
44] identifies three potential mechanisms involving the processes of word coinage, phonetic mutation, and lexical replacement. First, the under-representation of identical consonant sequences may result from a word creation bias, favoring lexical items that lack identical adjacent consonants. Second, while inefficient forms with identical consonant sequences are not entirely avoided, they are prone to phonetic changes that modify their sounds (e.g., the change from
bibere to
beivre in Old French). Third, words exhibiting this sound pattern may be more likely to be replaced by alternative words that do not contain such sequences.
Given the limited understanding of the mechanisms underlying efficient patterns, Cathcart [
44] investigated the role of the three mechanisms in lexical evolution, focusing on identical consonant sequences separated by vowels within morpheme boundaries (e.g.,
bibliography). Using phylogenetic modeling, a computational approach that reconstructs historical language relationships to trace evolutionary trajectories, the study analyzed the evolution of lexical items across language families such as Austronesian, Semitic, and Uralic. The findings show that the under-representation of identical consonant sequences is primarily due to lower birth rates of such words compared to those without identical consonants. While mutational processes that remove these sequences also contribute to the trend, they appear to play a less significant role. Notably, the study found no evidence supporting lexical replacement as a mechanism for this under-representation.
Considering that inefficient forms tend to be retained rather than replaced in the lexicon, Cathcart [
44] further examined whether languages mitigate their negative impact on communicative efficiency. An analysis of basic vocabulary reveals that words with identical consonant sequences are more likely to be removed from basic vocabulary to denote less basic and less frequent concepts. This pattern reflects a general disfavor towards identical consonant sequences, despite their persistence in the lexicon.
The study also hypothesized that words with identical consonant sequences are less likely to enter basic vocabulary and more likely to undergo phonetic mutation if they are basic terms. However, this trend was found to be inconsistent across the language families examined. The results suggest that such patterns are influenced by language-specific factors, such as phonological constraints, historical developments, and sociolinguistic pressures. For instance, in Arabic, where word structure is heavily reliant on consonantal arrangements, there are strong constraints against identical consonant sequences [
42]. In contrast, languages with simpler phonetic inventories may be more tolerant of this sound pattern, and others (e.g., Mandarin Chinese) even use reduplication, a process resulting in identical adjacent consonants, as a word-formation strategy [
45]. The interaction between language-specific features and communicative efficiency presents a noteworthy avenue for future research, particularly in understanding how languages favoring identical consonant sequences achieve and maintain communicative efficiency.
The study highlights the prominent role of creation bias in generating efficient patterns that avoid identical consonant sequences. As noted by the researcher (p. 7), other phonological processes, however, such as vowel harmony and assimilation, also warrant attention. These processes, unlike identical consonant avoidance, render sounds more similar to their neighbors. Future work could address how such contrasting phenomena might be unified under an efficiency framework.
Moreover, a notable challenge to the efficiency account lies in the potential conflict between communicative efficiency and learnability in the case of identical consonant avoidance. For instance, children exhibit a preference for reduplication in their speech owing to its simplicity and learnability, producing words such as
mama,
dada and
bye-bye [
46]
. This feature may be replaced by more adult-like speech patterns when children grow older. While Cathcart [
44] briefly mentions the phenomenon to explain the retention of words with identical consonant sequences (p. 7), it is essential to explore how the conflict between communicative efficiency and learnability can be resolved, as highlighted by Gibson et al. [
30].
One possibility is that the need for simplicity would be overshadowed by the need to distinguish different words through different consonants as children’s vocabularies are expanding. Furthermore, developmental advances in cognitive processing capacity may reduce reliance on simplicity constraints, enabling children to handle more complex phonological structures. If the pressure towards simplicity indeed wanes, a critical question for future research is whether children’s lexicon and its development reflect a dynamically shifting balance between simplicity and informativeness.
4.2. Grammar
It has been argued that word orders across languages are optimized to support efficient communication [
47]. Prior studies taking perspectives from dependency length or information density have suggested that word orders are shaped to minimize cognitive loads during both language production and comprehension (e.g., [
48,
49,
50]). Specifically, languages tend to favor word orders that minimize dependency length (
i.e., the distance between syntactically related words within a sentence) [
48]. For instance, subjects and objects are syntactically related to verbs because they are arguments the verb requires to complete the action or state described in the sentence. Thus, the principle of dependency length minimization predicts that speakers tend to choose the structure that results in shorter distances between the verb and its dependents (subject and object). Meanwhile, languages prefer word orders that enhance predictability regarding subsequent information [
49]. Previous research also indicates that word orders reflect an efficient trade-off between reducing dependency distances and mitigating ambiguity [
47]. Despite these insights, the evolutionary mechanisms that drive word orders towards communicative efficiency remain inadequately understood.
Under such a research context, Hahn and Xu’s study [
51] examined two dominant word orders,
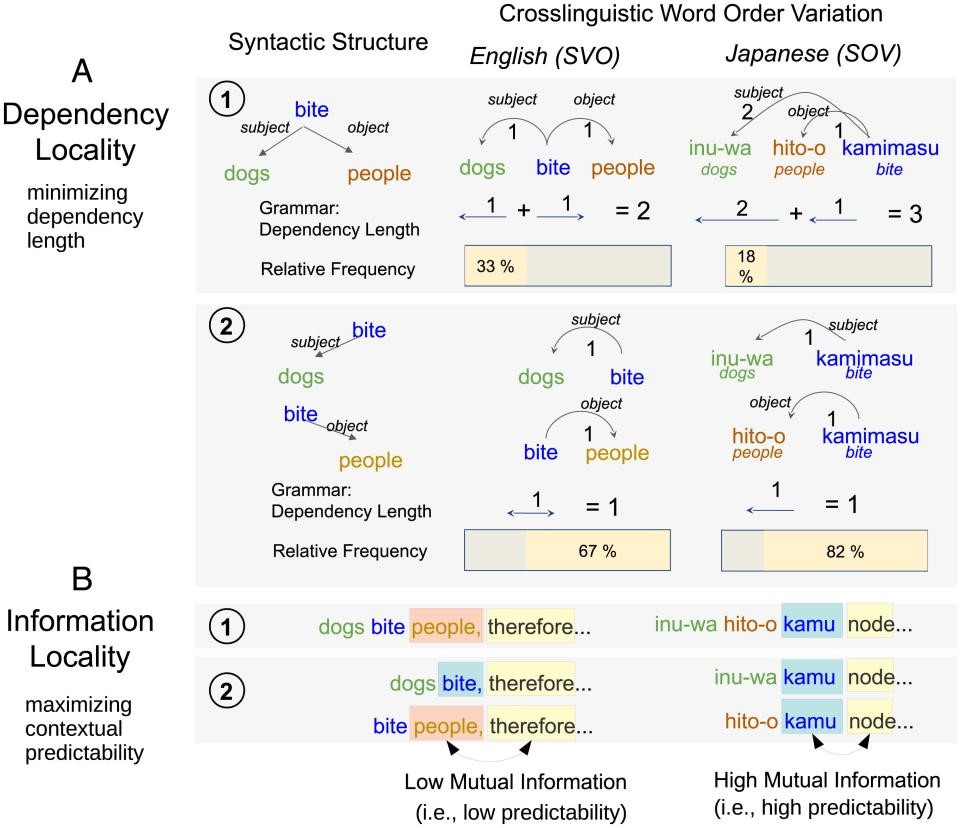
i.e., SVO (Subject-Verb-Object) and SOV (Subject-Object-Verb), from both synchronic and diachronic perspectives, aiming to elucidate the potential mechanisms contributing to the communicative efficiency of these structures. Their study conceptualizes efficiency as a balance between the pressures for dependency locality and information locality. Dependency locality refers to the minimization of dependency length for simplicity, whereas information locality pertains to the maximization of contextual predictability for informativeness. These pressures operate in opposition within word order systems. As illustrated in
(A1), SVO order is more efficient with respect to dependency locality than SOV order, as the former maintains an equal distance between the subject and the object in relation to the verb. In contrast, SOV order consistently positions the verb at the end of the sentence, regardless of the absence of subject or object in OV or SV structures, thus improving sentence-final predictability, as shown in
(B1,B2).
. Dependency locality and information locality of SVO and SOV orders. Panel (<b>A1</b>) shows that the dependency distances between the subject, the object, and the verb are shorter in SVO order than in SOV order. Panel (<b>A2</b>) illustrates that the difference in distance length between SVO and SOV orders is neutralized when either subject or object arguments are omitted from the syntactic structure. Panel (<b>B</b>) demonstrates the consistent verb-final positioning in SOV constructions, which remains stable regardless of argument omission, thereby yielding higher predictability of syntactic boundaries. This graphic is from [
51], licensed under the CC BY-NC-ND 4.0 license.
The researchers firstly assessed the efficiency of both word orders across 80 languages from 17 distinct language families. Their findings reveal that both SVO and SOV orders are closer to the Pareto frontier than constructed baseline word orders, suggesting that both reflect an efficient trade-off between the competing pressures of dependency locality and information locality. Furthermore, the results show that compared with SVO languages, SOV languages exhibit a stronger orientation towards information locality at the expense of dependency locality. Thus, the cross-linguistic variation between SVO and SOV orders can be attributed to the differences in the prioritization of two pressures, viz., information locality versus distance locality.
However, their further analysis reveals that, in actual usage, languages tend to accommodate both types of locality rather than adhering strictly to one end of the optimization spectrum. For example, SOV languages often favor the omission of subjects or objects, or employ intransitive structures more frequently. These strategies help mitigate the disadvantage of SOV order with respect to distance locality, as illustrated in (A2). In other words, SOV languages optimize information locality through grammar while simultaneously optimizing dependency locality through usage patterns that avoid the co-expression of subject and object. This joint optimization is achieved through the co-adaptation between grammar and usage.
Moreover, Hahn and Xu’s study [
51] simulated word order evolution using a drift model to represent random processes. By comparing attested word order changes with those generated by random drifts, the analysis demonstrated that observed changes in word order more closely align with efficiency-driven adaptation than with random processes. These findings suggest that communicative efficiency likely acts as a selective pressure in word order evolution, though other factors, such as language lineage, may also contribute to the observed patterns.
To sum up, from a diachronic perspective, the study indicates selection as a pivotal mechanism in driving language evolution and generating efficient word orders. From a synchronic perspective, the study reveals that both SVO and SOV word orders represent efficient structures that balance competing pressures, thus challenging the previous claim that SOV is less efficient than SVO [
52]. Moreover, the study suggests that SOV languages have the advantage of optimizing both distance locality and information locality through flexible usage patterns. This finding might potentially explain the phenomenon of SOV being the preferred word order in emergent sign languages, a phenomenon that has been documented in previous studies (e.g., [
53]) but has not been fully understood.
Nevertheless, the tendency of SOV languages to avoid the co-expression of subject and object warrants further exploration. One aspect not addressed in this study is the potential information loss resulting from the omission of subject or object in SOV structures, despite the apparent advantages of dependency length minimization. This consideration could suggest that the evaluation of informativeness should extend beyond contextual predictability to include information loss. Thus, the study opens the question of how the higher frequency of structures that avoid the co-expression of subject and object can be understood within the framework of communicative efficiency.
5. Efficiency and Language History
As has been illustrated by Hahn and Xu’s study on word order [
51], cross-linguistic variation can be attributed to languages’ prioritization of different communicative pressures. Notably, cultural and environmental differences also contribute to such variation. For instance, previous work on color terminology has shown that industrialized societies tend to develop more color terms than hunting and farming societies due to the increased communicative need to identify a broader range of objects based on colors [
54]. Similarly, the salience of particular objects within a given environment can drive languages to express their colors through distinct terms [
55]. In addition, an important yet under-explored factor in cross-linguistic variation is the historical constraint on language evolution. Research on word order has demonstrated that linguistic features are often lineage-specific in that extant features influence and constrain future developments [
56]. However, few studies have examined whether language history similarly contributes to the diversity of the lexicons across languages.
To investigate the role of historical constraint on lexical evolution, Twomey et al. [
57] conducted a study to determine whether the development of color vocabularies follows a specific pathway shaped by language history. This study employed computational models to simulate successor vocabularies,
i.e., the vocabularies formed by the addition of new terms to existing color vocabularies. The models were based on the assumption that color vocabularies, as efficient systems, balance complexity with information loss, which has been established by prior research (e.g., [
5,
28,
58]). Complexity was quantified by the number of color terms in the vocabulary, while information loss was measured as the difference between the actual color and the color represented by the term in the vocabulary. The objective of generating successor vocabularies was to identify which configurations could best achieve an efficient trade-off. Through this method, successor vocabularies were generated for the attested color systems from the World Color Survey (WCS), which includes data from 110 languages worldwide [
59]. For comparison, the study also constructed hypothetical vocabularies based on efficiency principles, but independent of existing color terms.
The results reveal that historically constrained vocabularies offer more limited possibilities for additions than the hypothetical vocabularies. In other words, the presence of existing terms constrains the range of possible successor vocabularies, which highlights the role of language history in shaping the evolution of color terminology. Specifically, languages are more likely to introduce new terms that are related to existing ones, rather than creating entirely new and unrelated terms, reflecting path-dependent evolutionary trajectories. This path dependency contributes to the diversification of color space partitioning across languages.
Additionally, the study generated precursor vocabularies,
i.e., the lexicons prior to the introduction of new terms, and identified color terms that are absent from current vocabularies and have previously been unobserved. This methodological approach makes significant contributions to evolution research by demonstrating the utility of efficiency-based models in the reconstruction of ancestral vocabularies.
While the study highlights language history as a significant factor influencing language evolution, it focuses on the addition of color terms and does not address color term loss, which is also a common phenomenon in lexical evolution, as documented by previous research [
60]. Future research could analyze evolutionary patterns by incorporating both the addition and loss of color terms to provide a more comprehensive understanding of lexical evolution. Furthermore, given the correlation between cultural factors and color naming established in prior studies (e.g., [
54,
61]), future work might also explore how cultural evolution intersects with changes in color categories over time.
6. General Discussion
This section synthesizes key findings from the reviewed studies, highlighting their contributions to our understanding of efficiency in language systems. The following discussion assesses the efficiency account’s explanatory power and limitations while proposing directions for future research.
6.1. Contributions
Altogether, the studies reviewed here lend substantial support to the plausibility of communicative efficiency as a contributing factor in shaping linguistic systems. These studies demonstrate that various linguistic features, such as different word formation strategies (e.g., word reuse versus compounding) [
37], word orders (e.g., SVO versus SOV) [
51], and grammatical categories (e.g., tense, number, evidentiality) [
41], all reflect a near-optimal trade-off between simplicity and informativeness. Such efficient patterns can be consistently explained by the efficiency principle: language universals may arise from the universal need to optimize communicative efficiency, while cross-linguistic variations likely stem from languages’ preferences for different communicative pressures that compete with one another.
The explanatory power of the communicative efficiency principle partly lies in its balanced framework, which integrates these competing pressures to conceptualize communicative efficiency. This conceptualization allows for the recognition that certain linguistic structures, such as compounds and SOV word order, also exhibit efficient patterns despite having previously been regarded as sub-optimal when evaluated solely through the lens of complexity [
37,
51]. As such, the efficiency account emerges as a plausible and inclusive interpretation, capable of encompassing a wide range of linguistic phenomena.
Furthermore, these studies highlight the complex array of factors that shape linguistic structures and their evolution. They suggest that efficient linguistic systems may result from both adaptive and non-adaptive constraints. Adaptive pressures towards communicative efficiency have been observed to shape linguistic forms in various ways, for instance, through removing inefficient words from the basic vocabulary [
44], and through co-adaptation between grammatical structures and usage frequencies [
51]. One illustrative case of this phenomenon is observed in word order evolution: when languages transition towards an SOV structure, they sometimes exhibit an increase in the frequency of intransitive sentences, as the avoidance of co-expressing subjects and objects in these sentences accommodates the pressure for distance locality while also maintaining information locality [
51]. At the same time, non-adaptive forces such as language history and creation bias have been shown to underlie efficient-looking phenomena, such as color naming [
57] and the under-representation of identical consonant sequences [
44], which may arise in the absence of direct communicative pressures.
6.2. Open Questions
The presence of non-adaptive forces in language evolution suggests that while the communicative efficiency account provides a compelling integrative framework, its alignment with the efficient structures observed in the studies reviewed does not necessarily confirm communicative efficiency as a direct driving force behind these structures. For example, null modeling studies have demonstrated that artificial systems devoid of communicative intent can nevertheless reproduce efficiency-like patterns, such as the correlation between word length and frequency [
1,
18] or between word length and homophony [
19,
20]. These findings highlight the importance of rigorous empirical validation. Specifically, to establish robust empirical support for the communicative efficiency account, it is crucial to reject the null hypothesis that observed efficient structures could emerge through mechanisms independent of communicative pressures. Although the studies examined in earlier sections demonstrate notable consistency between the efficiency account and the apparent efficiency of word formation [
37], word order [
51], and grammatical markers [
41], their experimental designs, particularly in comparing natural and artificial linguistic systems, do not adequately account for non-communicative factors. As a result, this methodological gap opens the possibility that the observed efficient structures may stem from processes unrelated to communicative efficiency.
Beyond the causal relationship between communicative efficiency and efficient structures, another significant issue the literature raises concerns the conceptualization of communicative efficiency itself. One major critique is that communication is not necessarily Pareto-efficient, as evidenced by the frequent occurrence of redundant or overlapping signals [
23]. For example, while negative correlations are found between word order and case marking, no such correlation exists between word order and verb agreement, or between verb agreement and case marking [
62]. Since both verb agreement and case marking serve to disambiguate grammatical roles, the presence of one feature is predicted to reduce the need for the other, resulting in an apparent trade-off. Therefore, the lack of correlation between these features suggests that natural languages may function as a synergistic system, where seemingly redundant information works together to reduce uncertainty, rather than adhering to an optimized trade-off.
The conceptualization of language as a Pareto-efficient system also raises concerns about the adequacy of reducing complex linguistic relationships to just two negatively correlated parameters [
23,
24]. Specifically, it remains unclear whether efficient trade-offs can still be observed when a third parameter is introduced. As discussed in Section 4.2, the avoidance of co-expression of subjects and objects in SOV languages may be considered an efficient strategy for optimizing both information locality and dependency locality. However, the absence of subjects or objects could result in increased processing costs, requiring additional effort to retrieve the relevant information from context. It is not immediately clear how the bivariate efficiency model accommodating only two parameters can incorporate the increased processing cost as an additional factor.
In addition, the efficiency account posits that strict SVO and SOV languages prioritize dependency locality (minimizing distances between syntactically linked elements) and information locality (maximizing contextual predictability), respectively [
51]. Under this framework, languages with flexible word orders are predicted to occupy an intermediate position, falling between the extremes of strict SVO and SOV languages in terms of contextual predictability. Nevertheless, flexible word orders are often accompanied by case marking as a compensatory strategy, which can add additional information and mitigate the unpredictability arising from variable word orders (e.g., [
62,
63]). This raises a question: how do trade-off models capture the interaction between compensatory strategies (such as case marking) and word order in shaping information locality? This question suggests that such bivariate models may risk oversimplifying the complexities of language structure and efficiency, as they do not seem to account for the nuanced role of additional linguistic features.
Despite these challenges to efficiency-based explanations, several behavioral studies have demonstrated that communicative pressures influence language learning and production. For instance, toddlers expect communication to be efficient, which shapes how they interpret new communicative cues [
64]. They consistently prefer direct interpretations that minimize processing costs and show a tendency to reinterpret sub-optimal cues to maximize informativeness. Similarly, language learning experiments have shown that learners actively adjust their input when it requires additional effort or when they are under pressure to balance accuracy and efficiency [
65,
66,
67]. These findings suggest that learners play an active role in negotiating trade-offs between complexity and informativeness. Therefore, while stochastic models can generate patterns that appear efficient through random processes, it is unlikely that human language is entirely free from communicative pressures, given humans’ active participation in communicative activities and their expectations for efficient communication.
In summary, while the principle of communicative efficiency provides a compelling explanation for many linguistic structures that appear optimized for communication, it is evident that communicative efficiency is not the sole determinant of linguistic structure. Efficient trade-offs may not always emerge directly from communicative pressures. Instead, the interplay of stochastic processes, language-internal constraints (e.g., phonotactics), language history, social factors, and communicative pressures likely shapes linguistic structures in a multifactorial way. Therefore, rather than negating the role of communicative efficiency, the challenges to the efficiency account raise two important questions: (1) to what extent does communicative efficiency shape linguistic structures? and (2) to what extent is it adequate to conceptualize efficiency solely in terms of two inverse parameters?
6.3. Future Directions
The debate surrounding the communicative efficiency principle, especially whether linguistic structures evolve in response to communicative efficiency or whether efficient patterns are byproducts of other mechanisms, remains a complex challenge. To advance this discourse, future research in this area should adopt multidimensional frameworks that transcend simplistic correlational analyses.
One suggestion made by Levshina is to drop the term “trade-off” entirely and instead conduct multivariate causal analyses to disentangle the direction of causality [
24]. For instance, using the Fast Causal Inference algorithm, Levshina’s work [
23] shows a greater probability of a directional relationship from word order to case marking than the reverse, which aligns with previous findings that a rigid word order can lead to the loss of case marking (e.g., [
62,
63]). Her multivariate causal analyses also reveal discernible yet comparatively modest causal pathways from semantic specificity and verb-centered argument structure to case-marking. These findings underscore the methodological superiority of multivariate frameworks in investigating interdependent relationships between multiple co-varying linguistic features.
Nevertheless, while bivariate efficiency models simplify complex linguistic relationships into two inverse parameters, they have proven effective in modeling language usage and reconstructing ancestral vocabulary, as parsimonious parameter setups help keep computational demands manageable. For example, Towmey et al.’s study [
57] on the reconstruction of ancestral color terms demonstrates the utility of these models. Therefore, future research could integrate multivariate causal analyses alongside trade-off models to disentangle causal relationships rather than discard trade-off models.
In relation to the role of communicative efficiency as the driving force in linguistic evolution, future studies should also test the efficiency account against null models, which simulate linguistic evolution in the absence of communicative pressures. As shown in previous works (e.g., [
19,
20,
21]), null models provide a valuable baseline for assessing whether observed efficient patterns in language arise from communicative pressures or emerge as byproducts of neutral processes. While these models do not directly identify the driving forces behind linguistic evolution, they offer important comparative data. If real-world languages systematically deviate from the patterns predicted by null models, showing greater efficiency, this could provide stronger evidence in support of the efficiency account.
To better elucidate the driving forces behind linguistic patterns, it is crucial to explore the interaction between communicative efficiency and other factors, especially sociocultural and environmental influences. Under the efficiency framework, cross-linguistic variation has been ascribed to languages prioritizing different communicative pressures [
51], which raises the question of why languages exhibit distinct preferences. Addressing this question necessitates examining local communicative needs shaped by local cultures and environments. At the lexical level, previous studies have shown that cultural factors influence how languages partition color space [
54,
61], while environments affect whether languages develop distinct forms for concepts like ice and snow [
68]. At the grammatical level, previous research has suggested that simpler morphological systems are often found in languages spoken by larger populations, covering wider geographic areas, and characterized by more intense language contact [
69]. These conditions, which often include adult learners, may favor linguistic simplicity to facilitate adults’ language learning. Given the influence of local communicative needs on linguistic structures, future research could explore how different local communicative needs lead languages to resolve competing pressures in different ways. Likewise, an important question in linguistic evolution naturally arises as to whether languages evolve and adapt in response to the changes in local communicative needs over time.
It is equally important to extend the framework to include linguistic phenomena that remain under-explored in the literature on communicative efficiency. For example, Binding Theory states that English reflexive pronouns must be locally bound within the same clause [
70], whereas languages like Mandarin Chinese and Japanese permit long-distance binding, where reflexives can take antecedents outside the local clause. Further research is needed to explore how the principle of communicative efficiency, which is often invoked to explain broad syntactic patterns (e.g., word order), can also account for finer-grained grammatical phenomena, such as reflexive binding and its cross-linguistic variation. Testing the application of the efficiency account across a broader range of phenomena would provide further evidence regarding its generalizability.
Lastly, a more challenging task for future research involves analyzing the efficiency of linguistic structures in conversational contexts. While some structures may appear ambiguous, their meanings can be easily resolved in conversation. This means that they do not necessarily result in information loss, contrary to what information-theoretic models would typically predict. Another consideration is communicative goals. Current models of communicative efficiency emphasize clarity and specificity; in conversational settings, however, the degree of specificity required is highly context-dependent. For instance, speakers may use less specific expressions when precision is unnecessary to achieve their communicative goals. Given the dynamic nature of real-life communication, future research could move beyond simplified models that analyze words and sentences in isolation. As proposed by Kemp et al. [
28], a promising approach is to measure informativeness by assessing how much information a word adds to an already-established context.
7. Conclusions
In general, the studies reviewed herein highlight the explanatory power of the principle of communicative efficiency, which offers a coherent framework for understanding the efficiency observed in both the lexicon and grammar, both synchronic patterns and language evolution, and in both cross-linguistic universals and variations. The efficiency framework integrates insights from linguistic typology, computer science, cognitive science, and anthropology, conceptualizing efficiency as a balance between the competing pressures of simplicity and informativeness. Additionally, by incorporating methodologies from information theory, it provides a computationally measurable approach to analyzing efficiency in terms of these competing pressures. Thus, as an integrative and empirically supported construct, the principle of communicative efficiency has the potential to capture a broader range of linguistic phenomena beyond those discussed here.
However, three critical issues warrant attention to refine and expand the efficiency framework. First, many studies in this area model efficiency as binary trade-offs, often overlooking complementary strategies and additional factors, such as sociocultural and environmental variables, that mediate optimization processes. This may lead to an oversimplification of linguistic complexity. Second, while many studies focus on the manifestation of efficiency in various linguistic structures, they often neglect to identify the underlying causal mechanisms. Future research should employ methodological innovations to clarify the role of communicative efficiency in language evolution, such as null models to isolate communicative pressures from random drift or multivariate causal analyses to disentangle competing influences. These approaches would help resolve the fundamental theoretical question of whether observed efficient structures reflect direct optimization for efficient communication or emerge indirectly as byproducts of non-functional mechanisms. Third, greater attention should be paid to under-explored areas, such as finer-grained grammatical phenomena and multi-modal communication (see [
71]), which may offer valuable opportunities for theoretical advancements.
Author Contributions
Conceptualization: Y.J. and Y.W.; Writing, Review & Editing: Y.J. and Y.W.; Supervision: Y.W.; Funding Acquisition: Y.W.
Ethics Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Funding
This work was funded by the Major Project of the National Social Science Fund of China (grant number 18ZDA292).
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
1.
Miller GA. Some effects of intermittent silence.
Am. J. Psychol. 1957,
70, 311–314.
[Google Scholar]
2.
Li W. Random texts exhibit zipf’s-law-like word frequency distribution.
IEEE Trans. Inf. Theory 1992,
38, 1842–1845.
[Google Scholar]
3.
Kemp C, Regier T. Kinship categories across languages reflect general communicative principles.
Science 2012,
336, 1049–1054.
[Google Scholar]
4.
Xu Y, Regier T, Malt BC. Historical semantic chaining and efficient communication: The case of container names.
Cogn. Sci. 2016,
40, 2081–2094.
[Google Scholar]
5.
Regier T, Kemp C, Kay P. Word meanings across languages support efficient communication. In The Handbook of Language Emergence; MacWhinney B, O’Grady W, Eds.; Wiley Online Library: Hoboken, NJ, USA, 2015; pp. 237–263.
6.
Chomsky N, Lasnik H. Filters and control.
Linguist. Inq. 1977,
8, 425–504.
[Google Scholar]
7.
Miller GA, Chomsky N. Finitary models of language users. In Handbook of Mathematical Psychology, 2nd ed.; Luce RD, Bush RR, Galanter E, Eds.; Wiley: New York, NY, USA, 1963; Volume 2, pp. 419–491.
8.
Labov W. Principles of Linguistic Change. Vol. 1: Internal Features; Blackwell: Oxford, UK, 1994.
9.
Eckert P, Labov W. Phonetics, phonology and social meaning.
J. Sociolinguist. 2017,
21, 467–496.
[Google Scholar]
10.
Newberry MG, Ahern CA, Clark R, Plotkin JB. Detecting evolutionary forces in language change.
Nature 2017,
551, 223–226.
[Google Scholar]
11.
Haspelmath M. Optimality and diachronic adaptation.
Z. Sprachwiss. 1999,
18, 180–205.
[Google Scholar]
12.
Croft W. Typology and Universals, 2nd ed.; Cambridge University Press: Cambridge, UK, 2003.
13.
Bybee J. Language, Usage and Cognition; Cambridge University Press: Cambridge, UK, 2010.
14.
Fedorenko E, Piantadosi ST, Gibson EA. Language is primarily a tool for communication rather than thought.
Nature 2024,
630, 575–586.
[Google Scholar]
15.
Hudson Kam CL, Newport EL. Regularizing unpredictable variation: The roles of adult and child learners in language formation and change.
Lang. Learn. Dev. 2005,
1, 151–195.
[Google Scholar]
16.
Zipf GK. Human Behavior and the Principle of Least Effort; Addison-Wesley Press: Cambridge, MA, USA, 1949.
17.
Piantadosi ST, Tily H, Gibson E. The communicative function of ambiguity in language.
Cognition 2012,
122, 280–291.
[Google Scholar]
18.
Ferrer i Cancho R, Moscoso del Prado Martín F.
Information content versus word length in random typing. J. Stat. Mech. 2011,
2011, L12002.
[Google Scholar]
19.
Caplan S, Kodner J, Yang C. Miller’s monkey updated: Communicative efficiency and the statistics of words in natural language.
Cognition 2020,
205, 104466.
[Google Scholar]
20.
Trott S, Bergen B. Why do human languages have homophones?
Cognition 2020,
205, 104449.
[Google Scholar]
21.
Koshevoy A, Dautriche I, Morin O. Why do some words have more meanings than others? A true neutral model for the meaning-frequency correlation.
Proc. Annu. Meet. Cogn. Sci. Soc. 2023,
45, 2296–2303.
[Google Scholar]
22.
Pimentel T. On the Optimality of the Lexicon, University of Cambridge, Cambridge, 2023. Apollo-University of Cambridge Repository. Available online: https://doi.org/10.17863/CAM.108081 (accessed on 25 March 2025).
23.
Levshina N. Cross-linguistic trade-offs and causal relationships between cues to grammatical subject and object, and the problem of efficiency-related explanations.
Front. Psychol. 2021,
12, 648200.
[Google Scholar]
24.
Levshina N. Efficient trade-offs as explanations in functional linguistics: Some problems and an alternative proposal.
Rev. ABRALIN 2020,
19, 50–78.
[Google Scholar]
25.
Becker L. Levshina, Natalia: Communicative efficiency: Language structure and use.
Linguist. Typol. 2024,
28, 367–378.
[Google Scholar]
26.
Haiman J. Competing motivations. In The Oxford Handbook of Linguistic Typology; Song J, Ed.; Oxford University Press: Oxford, UK, 2010; pp. 148–165.
27.
Du Bois JW. Competing motivations. In Iconicity in Syntax; Haiman J, Ed.; Benjamins: Amsterdam, The Netherlands, 1985; pp. 343–365.
28.
Kemp C, Xu Y, Regier T. Semantic typology and efficient communication.
Annu. Rev. Linguist. 2018,
4, 109–128.
[Google Scholar]
29.
Piantadosi ST, Tily H, Gibson E. Word lengths are optimized for efficient communication.
Proc. Natl. Acad. Sci. USA 2011,
108, 3526–3529.
[Google Scholar]
30.
Gibson E, Futrell R, Piantadosi ST, Dautriche I, Mahowald K, Bergen L, et al. How efficiency shapes human language.
Trends Cogn. Sci. 2019,
23, 389–407.
[Google Scholar]
31.
Shannon CE. A mathematical theory of communication.
Bell Syst. Tech. J. 1948,
27, 379–423.
[Google Scholar]
32.
Cover TM, Thomas JA. Elements of Information Theory, 2nd ed.; Wiley Online Library: Hoboken, NJ, USA, 2006.
33.
Tishby N, Pereira F, Bialek W. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; Tishby N, Pereira FC, Hajek B, Screenivas RS, Eds.; University of Illinois Press: Monticello, IL, USA, 1999; pp. 368–377.
34.
Kullback S, Leibler RA. On information and sufficiency.
Ann. Math. Stat. 1951,
22, 79–86.
[Google Scholar]
35.
Xu Y, Duong K, Malt BC, Jiang S, Srinivasan M. Conceptual relations predict colexification across languages.
Cognition 2020,
201, 104280.
[Google Scholar]
36.
Downing P. On the creation and use of English compound nouns.
Language 1977,
53, 810–842.
[Google Scholar]
37.
Xu A, Kemp C, Frermann L, Xu Y. Word reuse and combination support efficient communication of emerging concepts.
Proc. Natl. Acad. Sci. USA 2024,
121, e2406971121.
[Google Scholar]
38.
Pimentel T, Nikkarinen I, Mahowald K, Cotterell R, Blasi D. How (non-)optimal is the lexicon? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Toutanova K, Rumshisky A, Zettlemoyer L, Hakkani-Tur D, Beltagy I, Bethard S, et al., Eds.; Association for Computational Linguistics: Online, 2021; pp. 4426–4438.
39.
Xu Y, Liu E, Regier T. Numeral systems across languages support efficient communication: From approximate numerosity to recursion.
Open Mind 2020,
4, 57–70.
[Google Scholar]
40.
Haspelmath M. Explaining grammatical coding asymmetries: Form-frequency correspondences and predictability.
J. Linguist. 2021,
57, 605–633.
[Google Scholar]
41.
Mollica F, Bacon G, Zaslavsky N, Xu Y, Regier T, Kemp C. The forms and meanings of grammatical markers support efficient communication.
Proc. Natl. Acad. Sci. USA 2021,
118, e2025993118.
[Google Scholar]
42.
Frisch SA, Pierrehumbert JB, Broe MB. Similarity avoidance and the OCP.
Nat. Lang. Linguist. Theory 2004,
22, 179–228.
[Google Scholar]
43.
Cohen-Goldberg AM. Phonological competition within the word: Evidence from the phoneme similarity effect in spoken production.
J. Mem. Lang. 2012,
67, 184–198.
[Google Scholar]
44.
Cathcart C. Multiple evolutionary pressures shape identical consonant avoidance in the world’s languages.
Proc. Natl. Acad. Sci. USA 2024,
121, e2316677121.
[Google Scholar]
45.
Xu D. Reduplication in languages: A case study of languages of China. In Plurality and Classifiers across Languages in China; Xu D, Ed.; De Gruyter: Berlin, Germany, 2013; pp. 43–64.
46.
Dressler W, Dziubalska-Kołaczyk K, Gagarina N, Kilani-Schoch M. Reduplication in child language. In Studies on Reduplication; Hurch B, Ed.; De Gruyter: Berlin, Germany, 2005; pp. 455–474.
47.
Hahn M, Jurafsky D, Futrell R. Universals of word order reflect optimization of grammars for efficient communication.
Proc. Natl. Acad. Sci. USA 2020,
117, 2347–2353.
[Google Scholar]
48.
Liu H. Dependency distance as a metric of language comprehension difficulty.
J. Cogn. Sci. 2008,
9, 159–191.
[Google Scholar]
49.
Futrell R, Mahowald K, Gibson E. Large-scale evidence of dependency length minimization in 37 languages.
Proc. Natl. Acad. Sci. USA 2015,
112, 10336–10341.
[Google Scholar]
50.
Levy R, Jaeger TF. Speakers optimize information density through syntactic reduction. In Advances in Neural Information Processing Systems; Schölkopf B, Platt J, Hofmann T, Eds.; MIT Press: Cambridge, MA, USA, 2007; pp. 849–856.
51.
Hahn M, Xu Y. Crosslinguistic word order variation reflects evolutionary pressures of dependency and information locality.
Proc. Natl. Acad. Sci. USA 2022,
119, e2122604119.
[Google Scholar]
52.
Maurits L, Navarro D, Perfors A. Why are some word orders more common than others? A uniform information density account. In Advances in Neural Information Processing Systems; Lafferty JD, Williams CKI, Shawe-Taylor J, Zemel RS, Culotta A, Eds.; Curran Associates, Inc.: San Francisco, CA, USA, 2010; Volume 23, pp. 1585–1593.
53.
Sandler W, Meir I, Padden C, Aronoff M. The emergence of grammar: Systematic structure in a new language.
Proc. Natl. Acad. Sci. USA 2005,
102, 2661–2665.
[Google Scholar]
54.
Gibson E, Futrell R, Jara-Ettinger J, Mahowald K, Bergen L, Ratnasingam S, et al. Color naming across languages reflects color use.
Proc. Natl. Acad. Sci. USA 2017,
114, 10785–10790.
[Google Scholar]
55.
Twomey CR, Roberts G, Brainard DH, Plotkin JB. What we talk about when we talk about colors.
Proc. Natl. Acad. Sci. USA 2021,
118, e2109237118.
[Google Scholar]
56.
Dunn M, Greenhill SJ, Levinson SC, Gray RD. Evolved structure of language shows lineage-specific trends in word-order universals.
Nature 2011,
473, 79–82.
[Google Scholar]
57.
Twomey CR, Brainard DH, Plotkin JB. History constrains the evolution of efficient color naming, enabling historical inference.
Proc. Natl. Acad. Sci. USA 2024,
121, e2313603121.
[Google Scholar]
58.
Zaslavsky N, Kemp C, Regier T, Tishby N. Efficient compression in color naming and its evolution.
Proc. Natl. Acad. Sci. USA 2018,
115, 7937–7942.
[Google Scholar]
59.
Kay P, Berlin B, Maaffi L, Merrifield W, Cook R. The World Color Survey; CLSI: Stanford, CA, USA, 2009.
60.
Haynie HJ, Bowern C. Phylogenetic approach to the evolution of color term systems.
Proc. Natl. Acad. Sci. USA 2016,
113, 13666–13671.
[Google Scholar]
61.
Kay P, Maffi L. Color appearance and the emergence and evolution of basic color lexicons.
Am. Anthropol. 1999,
101, 743–760.
[Google Scholar]
62.
Sinnemäki K. Complexity trade-offs in core argument marking. In Language Complexity: Typology, Contact, Change; Miestamo M, Sinnemäki K, Karlsson F, Eds.; John Benjamins: Amsterdam, The Netherlands, 2008; pp. 67–88.
63.
Fedzechkina M, Newport EL, Jaeger TF. Balancing effort and information transmission during language acquisition: Evidence from word order and case marking.
Cogn. Sci. 2017,
41, 416–446.
[Google Scholar]
64.
Aguirre M, Brun M, Morin O, Reboul A, Mascaro O. Expectations of processing ease, informativeness, and accuracy guide toddlers’ processing of novel communicative cues.
Cogn. Sci. 2023,
47, e13373.
[Google Scholar]
65.
Fedzechkina M, Jaeger TF, Newport EL. Language learners restructure their input to facilitate efficient communication.
Proc. Natl. Acad. Sci. USA 2012,
109, 17897–17902.
[Google Scholar]
66.
Kanwal J, Smith K, Culbertson J, Kirby S. Zipf’s law of abbreviation and the principle of least effort: Language users optimise a miniature lexicon for efficient communication.
Cognition 2017,
165, 45–52.
[Google Scholar]
67.
Fedzechkina M, Jaeger TF. Production efficiency can cause grammatical change: Learners deviate from the input to better balance efficiency against robust message transmission.
Cognition 2020,
196, 104115.
[Google Scholar]
68.
Regier T, Carstensen A, Kemp C. Languages support efficient communication about the environment: Words for snow revisited.
PLoS ONE 2016,
11, e0151138.
[Google Scholar]
69.
Lupyan G, Dale R. Language structure is partly determined by social structure.
PLoS ONE 2010,
5, e8559.
[Google Scholar]
70.
Chomsky N. Lectures on Government and Binding: The Pisa Lectures; De Gruyter: Berlin, Germany, 1993.
71.
Grzyb B, Frank SL, Vigliocco G. Communicative efficiency in multimodal language directed at children and adults.
J. Exp. Psychol. Gen. 2024,
153, 1904–1919.
[Google Scholar]